
[ad_1]
Understanding and mitigating hallucinations in vision-language models (VLVMs) is an emerging field of research that addresses the generation of coherent but factually incorrect responses by these advanced AI systems. As VLVMs increasingly integrate text and visual inputs to generate responses, the accuracy of these outputs becomes crucial, especially in settings where precision is paramount, such as medical diagnostics or autonomous driving.
Hallucinations in VLVMs typically manifest as plausible yet incorrect details generated about an image. These inaccuracies pose significant risks, potentially misinforming decisions in critical applications. The challenge lies in detecting these errors and developing methods to mitigate them effectively, ensuring the reliability of VLVM outputs.
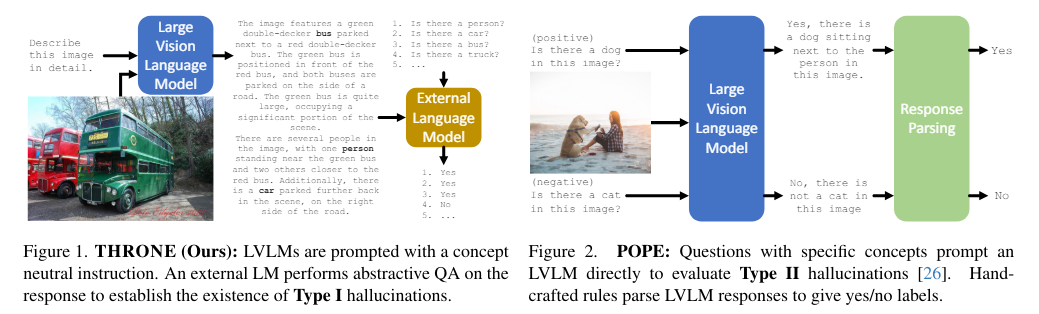
Most existing benchmarks for evaluating hallucinations in VLVMs focus on responses to constrained query formats, such as yes/no questions about specific objects or attributes within an image. These benchmarks often fail to measure more complex, open-ended hallucinations that can occur in varied real-world applications. As a result, there is a significant gap in the ability to fully understand and mitigate the broader spectrum of hallucinations that VLVMs can produce.
Researchers from the University of Oxford, AWS AI Labs, introduced a new framework called THRONE (Text-from-image Hallucination Recognition with Object-probes for open-ended Evaluation) to address this gap. THRONE is designed to assess Type I hallucinations, those that occur in response to open-ended prompts requiring detailed image descriptions. Unlike previous methods, THRONE uses publicly available language models to evaluate the hallucinations in free-form responses generated by various VLVMs, offering a more comprehensive and rigorous approach.
THRONE leverages multiple metrics to measure hallucinations across different VLVMs quantitatively. For example, it employs precision and recall metrics alongside a class-wise F0.5 score, emphasizing precision twice as much as recall. This scoring is particularly relevant in scenarios where false positives, incorrect but plausible responses, are more detrimental than false negatives.
An evaluation of THRONE’s effectiveness revealed insightful data about the prevalence and characteristics of hallucinations in current VLVMs. Despite the framework’s advanced approach, the results indicate that many VLVMs still struggle with a high rate of hallucinations. For instance, the framework detected that some of the evaluated models produce responses, with about 20% of the objects mentioned being hallucinations. This high rate of inaccuracies underscores the persistent challenge of reducing hallucinations and improving the reliability of VLVM outputs.

In conclusion, the THRONE framework represents a significant step forward in evaluating hallucinations in vision-language models, particularly addressing the complex issue of Type I hallucinations in free-form responses. While existing benchmarks have struggled to effectively measure these more nuanced errors, THRONE utilizes a novel combination of publicly available language models and a robust metric system, including precision, recall, and class-wise F0.5 scores. Despite these advances, the high rate of detected hallucinations, around 20% in some models, underscores the ongoing challenges and the necessity for further research to enhance the accuracy and reliability of VLVMs in practical applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
[ad_2]
Source link